PyTorch 实现 Opencv Canny 算法

使用PyTorch 实现Canny算法,相比于纯python实现,速度会更快,因为PyTorch api 使用很多c语言的底层模块,比如卷积。另外使用Pytorch可以很方便得利用cuda的加速,所以也在GPU并行运算上也有优势。
不过相比OpenCV c++的高效,PyTorch的实现显得更冗余,效率一般。但是PyTorch 使用张量、卷积来实现图像处理,保证一定效率的同时代码更简洁,另外比较重要的是,全过程使用python语言所以程序比较方进行调试,展示算法的中间处理过程。
程序运行
完整程序:https://github.com/qyzhizi/canny-algorithm.git
运行命令:
python pytorch-canny.py -v -i data/lena.png -gk 0 -L 100 -H 200
命令行参数:
-v: 展示中间过程处理的图片
-i: 图片路径
-gk: 高斯核大小,默认是3, 传入0则表示不使用高斯模糊处理
-L: 低阈值
-H: 高阈值
结果:

Canny 算法执行步骤
算法主要分为一下步骤:
- 高斯滤波
- 使用sobel 算子计算梯度(水平梯度, 垂直梯度)
- 计算梯度的幅值与方向
- 梯度的极大值抑制
- 滞后阈值
main 程序片段
def main():
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True, default="lena.png", help="Path to the image")
ap.add_argument("-v", "--verbose", action='store_true', default=False, help="Path to the image")
ap.add_argument("-gk", "--gaussian_kernel_size", type=int, default=3, help="Path to the image")
ap.add_argument("-L", "--threshold_low", type=int, default=20, help="Path to the image")
ap.add_argument("-H", "--threshold_high", type=int, default=50, help="Path to the image")
args = vars(ap.parse_args())
verbose = args["verbose"]
threshold_low = args["threshold_low"]
threshold_high = args["threshold_high"]
gaussian_kernel_size = args["gaussian_kernel_size"]
print("args: " , args)
# 把工作目录切换到当前文件夹所在目录
os.chdir(os.path.dirname(os.path.abspath(__file__)))
# 打印当前工作目录
if verbose:
print(os.getcwd())
# 读入一张图片,并转换为灰度图
im = Image.open(args["image"]).convert('L')
# 将图片数据转换为矩阵
im = np.array(im, dtype='float32')
# 将图片矩阵转换为pytorch tensor,并适配卷积输入的要求
im = torch.from_numpy(im.reshape((1, 1, im.shape[0], im.shape[1])))
if verbose:
print("im.shape: ", im.shape)
# 对图像进行高斯滤波,平滑图像,去除噪声
im = gaussian_blur(im, gaussian_kernel_size, verbose=verbose)
# sobel 算子进行边缘检测
gradient_v = functional_conv2d_vertical(im, verbose=verbose) # 竖直梯度
gradient_h = functional_conv2d_horizontal(im, verbose=verbose) # 水平梯度
# 计算梯度幅值
gradient_magnitude = get_gradient_magnitude(gradient_v, gradient_h, verbose=verbose)
# 计算梯度方向
gradient_direction_quantized = get_gradient_direction_quantized(gradient_v, gradient_h, verbose=verbose)
# 非极大值抑制
nms_tensor = nms(gradient_magnitude, gradient_direction_quantized, verbose=verbose)
# 阈值处理
# edge_detect = threshold(nms_tensor, low=threshold_low, high=threshold_high, weak=50, strong=255)
# 滞后阈值
edge_detect = hysteresis_threshold(nms_tensor, low=threshold_low, high=threshold_high)
if verbose:
print("edge_detect.shape: ", edge_detect.shape, "im.shape: ", im.shape)
plt.imshow(edge_detect.squeeze().detach().numpy(), cmap='gray')
plt.title("Edge Detection")
plt.show()
# 保存图片
save_edge_detect_as_image(edge_detect, "data/edge_detect.png", verbose=verbose)
save_edge_detect_and_origin_image_as_image(edge_detect, args["image"], "data/edge_detect_and_origin_image.png", verbose=verbose)
if __name__ == "__main__":
start_time = time.time()
print("programming strat")
main()
end_time = time.time()
print("time: ", end_time - start_time)
print("programming end")
高斯滤波
def dnorm(x: int, mu:int , sd:int)-> np.float32:
return 1 / (np.sqrt(2 * np.pi) * sd) * np.e ** (-np.power((x - mu) / sd, 2) / 2)
def gaussian_kernel(size: int, sigma: int=1, verbose: bool=False) -> np.ndarray:
kernel_1D = np.linspace(-(size // 2), size // 2, size)
for i in range(size):
kernel_1D[i] = dnorm(kernel_1D[i], 0, sigma)
if verbose:
print("kernel_1D: ", kernel_1D)
kernel_2D = np.outer(kernel_1D, kernel_1D)
if verbose:
print("kernel_2D: ", kernel_2D)
kernel_2D *= 1.0 / (kernel_2D.max() * size * size)# 归一化, 使得kernel_2D的最大值为1
if verbose:
print(kernel_2D.max())
print("kernel_2D: ", kernel_2D)
if verbose:
plt.imshow(kernel_2D, interpolation='none', cmap='gray')
plt.title("Kernel ( {}X{} )".format(size, size))
plt.show()
return kernel_2D
# 对图像进行高斯滤波,平滑图像,去除噪声
def gaussian_blur(image: torch.tensor, kernel_size: int, verbose=False) -> torch.tensor:
if kernel_size % 2 == 1 and kernel_size > 1 and kernel_size < 20:
kernel = gaussian_kernel(kernel_size, sigma=math.sqrt(kernel_size), verbose=verbose)
kernel = kernel.reshape((1, 1, kernel_size, kernel_size))
weight = torch.from_numpy(kernel).to(torch.float32)
# image padding kernel_size // 2, 使用原始图像的边缘像素进行填充
image = F.pad(image, (kernel_size // 2, kernel_size // 2, kernel_size // 2, kernel_size // 2), mode='reflect')
blur = F.conv2d(image, weight, padding=0)
if verbose:
plt.imshow(blur.squeeze().numpy(), cmap='gray')
plt.title("blur")
plt.show()
return blur
else:
return image
函数gaussian_blur :
def gaussian_blur(image: torch.tensor, kernel_size: int, verbose=False) -> torch.tensor:
gaussian_blur 实现了高斯滤波,首先调 gaussian_kernel 获取高斯核,然后转换为tensor类型,作为接下卷积的权重。
使用F.conv2d 进行卷积,卷积核为高斯核,卷积结果就是高斯模糊化后的图片。
sobel 算子计算梯度
# sobel 算子进行边缘检测
gradient_v = functional_conv2d_vertical(im, verbose=verbose) # 竖直梯度
gradient_h = functional_conv2d_horizontal(im, verbose=verbose) # 水平梯度
同样使用了卷积来计算梯度:F.conv2d(im, weight, stride=1, padding=0), 注意padding:im = F.pad(im, (1, 1, 1, 1), mode='replicate') , 这里使用了复制模式。使用补零或翻转的模式都不如复制模式好。opencv 的实现也是复制模式。
关于sobel 算子的原理,可以参考另外一篇文章: # Pytorch卷积实现边缘检测
functional_conv2d_vertical 函数 与 functional_conv2d_horizontal函数的代码:
def functional_conv2d_horizontal(im, verbose=False):
"""使用F.Conv2d进行边缘检测, 检测竖直方向的轮廓, 水平梯度,右方向为正方向
Args:
im (tensor): 输入的tensor图像
Returns:
tensor: 输出的tensor图像
"""
sobel_kernel = np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]], dtype='float32')
sobel_kernel = sobel_kernel.reshape((1, 1, 3, 3))
weight = torch.from_numpy(sobel_kernel)
im = F.pad(im, (1, 1, 1, 1), mode='replicate')
edge_detect = F.conv2d(im, weight, stride=1, padding=0)
if verbose:
plt.imshow(edge_detect.squeeze().detach().numpy(), cmap='gray')
plt.title("horizontal")
plt.show()
return edge_detect
def functional_conv2d_vertical(im, verbose=False):
"""使用F.Conv2d进行边缘检测, 检测水平方向的轮廓, 垂直梯度,向上为正方向
Args:
im (tensor): 输入的tensor图像
Returns:
tensor: 输出的tensor图像
"""
sobel_kernel = np.array([[1, 2, 1], [0, 0, 0], [-1, -2, -1]], dtype='float32')
sobel_kernel = sobel_kernel.reshape((1, 1, 3, 3))
weight = torch.from_numpy(sobel_kernel)
im = F.pad(im, (1, 1, 1, 1), mode='replicate')
edge_detect = F.conv2d(im, weight, stride=1, padding=0)
if verbose:
plt.imshow(edge_detect.squeeze().detach().numpy() , cmap='gray')
plt.title("vertical")
plt.show()
return edge_detect
计算梯度的幅值与方向
梯度幅值与方向将用于极大值抑制。
函数调用:
# 计算梯度幅值
gradient_magnitude = get_gradient_magnitude(gradient_v, gradient_h, verbose=verbose)
# 计算梯度方向
gradient_direction_quantized = get_gradient_direction_quantized(gradient_v, gradient_h, verbose=verbose)
计算幅值
默认使用L1范数, 在opencv 的实现中,如果sobel卷积核比较大,比如16x16 会使用L2范数。
参数:gradient_v 代表垂直方向的梯度,有正负值,向上为正方向。
gradient_h 代表水平方向的梯度,有正负值,右方向为正方向。
def get_gradient_magnitude(gradient_v: torch.tensor, gradient_h: torch.tensor, verbose=False, use_l2_norm=False) -> torch.tensor:
"""计算梯度幅值
"""
# 计算梯度的幅值
if use_l2_norm:
# use l2 norm
gradient_magnitude = torch.sqrt(gradient_v**2 + gradient_h**2)
else:
# use l1 norm
gradient_magnitude = torch.abs(gradient_v) + torch.abs(gradient_h)
# 将梯度幅值限制在0-255之间
# gradient_magnitude = gradient_magnitude * 255.0 / gradient_magnitude.max()
if verbose:
plt.imshow(gradient_magnitude.squeeze().numpy(), cmap='gray')
plt.title("Gradient Magnitude")
plt.show()
return gradient_magnitude
计算梯度方向
这里判断梯度方向时,会将梯度方向判定为[0, 45, 90, 135]之一,用如下图表示:
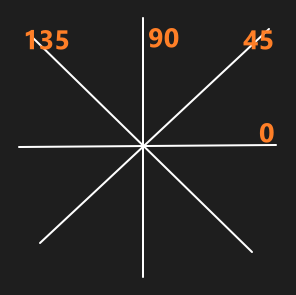
这里的划分标准是:
位于[(360-22.5), 360] [0,22.5] [(180-22.5), (180+22.5)] 区间判方向为0度
下图所示:
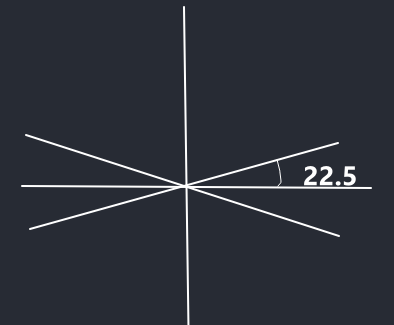
位于[(90-22.5), (90+22.5)] [(270-22.5), (270+22.5)] 区间判方向为90度.
如下图所示:
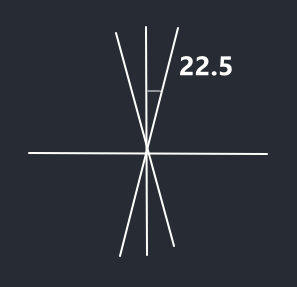 同理,位于
同理,位于[135-22.5, 135+22.5] or [315-22.5, 315+22.5]区间判方向为135度. 位于[45-22.5, 45+22.5] or [225-22.5, 225+22.5]判方向为45度
如下图所示:

实际计算过程中,[0, 45, 90, 135] 4个方向分别用[0, 1, 2, 3]表示。
例如:
# 将角度值转换为四个方向之一:0度,45度,90度,135度
gradient_direction_quantized = (torch.round(gradient_direction_deg / 45) % 4).int()
gradient_direction_quantized 是一个包含[0, 1, 2, 3]的tensor.
torch.round(gradient_direction_deg / 45) 这里会进行四舍五入,比如:torch.round((135+22.5) / 45) == torch.round(3.5) == 4
计算梯度方向函数:
def get_gradient_direction_quantized(gradient_v: torch.tensor, gradient_h: torch.tensor, verbose=False) -> torch.tensor:
"""计算梯度方向
将梯度方向转换为四个方向之一: 0度,45度,90度,135度, 分别用 0,1,2,3 表示。
"""
# 计算梯度方向, 以弧度为单位
gradient_direction = torch.atan2(gradient_v, gradient_h)
# 将梯度方向转换为角度值, 并将角度值转换为0-360度之间
gradient_direction_deg = torch.rad2deg(gradient_direction) + 180
# 将角度值转换为四个方向之一:0度,45度,90度,135度
gradient_direction_quantized = (torch.round(gradient_direction_deg / 45) % 4).int()
if verbose:
print("gradient_direction_quantized: ", gradient_direction_quantized)
return gradient_direction_quantized
梯度的极大值抑制
极大值抑制算法:
进行极大值抑制时会对周边先padding一圈0,然后对某个像素进行极大值抑制时,然后判断当前像素的方向,方向分别用0, 1, 2, 3表示,代表着0度、45度、90度,135度。假设当前像素是135度的方向,所以会比较135度方向上另外2个像素,如果当前像素的坐标是(0,0), 那么另两个像素的坐标就是(-1,1)(1,-1),注意即使另两个像素不是135度,依然选这两个坐标,另两个像素是不是135度不重要,至于为什么,我也不知道如何解释。这种情况下,遍历每个像素就得到了极大值抑制的结果。
可以使用pytorch 的卷积来实现, 先定义一个卷积:
nms_conv_op = torch.nn.Conv2d(in_channels=1,out_channels=3, kernel_size=3, stride=1, padding=1, bias=False)
它的输出通道为3, 这意味着卷积的通道为3 例如:
quantized_0_list = [[[0, 0, 0],[1, 0, 0],[0, 0, 0]],
[[0, 0, 0],[0, 1, 0],[0, 0, 0]],
[[0, 0, 0],[0, 0, 1],[0, 0, 0]]]
这是选取0度方向的卷积核,作用是选取该方向上的3个元素,每个卷积核选中某个方向上的一个元素。
第一个通道:[[0, 0, 0],[1, 0, 0],[0, 0, 0]] 将会选择当前元素左边的元素。第二个通道选择当前元素,第3个通道选择当前元素右边的元素。
45度、90度,135度 的情况也是类似,这里就不多赘述了。
由于有4个方向,因此会进行4次卷积.
假设输入gradient_magnitude的shape 是(1,1,n,m), 那么输出的nms_edge 的shape 是 (1,3,n,m) , 这里3 表示3通道,保存着对应位置某个方向上的3个元素。
mask_i = (gradient_direction_quantized == i).int(): 获取某个方向上的mask.
nms_direction_conv_mask_i = nms_direction_conv_i * mask_i: 将某次卷积的结果与mask_i 相乘,只选择掩码所标识位置的值。shape 是 (1,3,n,m),
nms_direction_conv_mask_max_i, _ = torch.max(nms_direction_conv_mask_i, dim=1): 最后选择nms_direction_conv_mask_i 维度1上(3通道)最大的值, nms_direction_conv_mask_max_i 的形状变为(1,1,n,m)
nms_edge = nms_edge + ((gradient_magnitude == nms_direction_conv_mask_max_i) * nms_direction_conv_mask_max_i)
nms_direction_conv_mask_max_i 中每个元素,表示该元素在i方向上最大的值, 但是这个最大值不一定是当前的元素。
(gradient_magnitude == nms_direction_conv_mask_max_i): 当前元素如果是最大的,那么选中,否者放弃。
(gradient_magnitude == nms_direction_conv_mask_max_i) 返回的0, 1的矩阵,所以还需乘nms_direction_conv_mask_max_i 来选中对应的元素,最后加入到最终的输出nms_edge。
完整程序:
def nms(gradient_magnitude: torch.tensor,
gradient_direction_quantized: torch.tensor,
verbose=False) -> torch.tensor:
"""非极大值抑制"""
nms_edge = torch.zeros_like(gradient_magnitude)
nms_conv_op = torch.nn.Conv2d(in_channels=1,out_channels=3,
kernel_size=3, stride=1,
padding=1, bias=False)
quantized_0_list = [[[0, 0, 0],[1, 0, 0],[0, 0, 0]],
[[0, 0, 0],[0, 1, 0],[0, 0, 0]],
[[0, 0, 0],[0, 0, 1],[0, 0, 0]]]
quantized_1_list = [[[0, 1, 0],[0, 0, 0],[0, 0, 0]],
[[0, 0, 0],[0, 1, 0],[0, 0, 0]],
[[0, 0, 0],[0, 0, 0],[0, 1, 0]]]
quantized_2_list = [[[0, 1, 0],[0, 0, 0],[0, 0, 0]],
[[0, 0, 0],[0, 1, 0],[0, 0, 0]],
[[0, 0, 0],[0, 0, 0],[0, 1, 0]]]
quantized_3_list = [[[1, 0, 0],[0, 0, 0],[0, 0, 0]],
[[0, 0, 0],[0, 1, 0],[0, 0, 0]],
[[0, 0, 0],[0, 0, 0],[0, 0, 1]]]
kernel_0 = torch.tensor(quantized_0_list, dtype=torch.float32)
kernel_1 = torch.tensor(quantized_1_list, dtype=torch.float32)
kernel_2 = torch.tensor(quantized_2_list, dtype=torch.float32)
kernel_3 = torch.tensor(quantized_3_list, dtype=torch.float32)
kernel_direction_quantized = [kernel_0,
kernel_1,
kernel_2,
kernel_3]
for i in range(4):
mask_i = (gradient_direction_quantized == i).int()
if verbose:
print("mask_i: ", mask_i)
nms_conv_op.weight.data = kernel_direction_quantized[i].reshape((3, 1, 3, 3))
nms_direction_conv_i = nms_conv_op(gradient_magnitude)
nms_direction_conv_mask_i = nms_direction_conv_i * mask_i
nms_direction_conv_mask_max_i, _ = torch.max(nms_direction_conv_mask_i, dim=1)
if verbose:
print("nms_direction_conv_mask_max_i: ", nms_direction_conv_mask_max_i)
print("nms_direction_i: ", nms_direction_conv_mask_max_i)
nms_edge = nms_edge + ((gradient_magnitude == nms_direction_conv_mask_max_i) *
nms_direction_conv_mask_max_i)
if verbose:
print("nms_edge: ", nms_edge)
# verbose = True
if verbose:
plt.imshow(nms_edge.squeeze().detach().numpy(), cmap='gray')
plt.title("Non-Maximum Suppression")
plt.show()
return nms_edge
滞后阈值
滞后阈值的目的是为了连接间断点,具有更好的鲁棒性。 例如:
# 普通双边阈值处理
edge_detect = threshold(nms_edge, low=threshold_low, high=threshold_high, weak=50, strong=255)
# 滞后阈值
edge_detect = hysteresis_threshold(nms_edge, low=threshold_low, high=threshold_high)
同样的命令:
python pytorch-canny.py -v -i data/lena.png -gk 0 -L 100 -H 200
使用滞后阈值的结果,普通双边阈值处理的结果分别是:

算法步骤:
hysteresis_threshold输入:nms_edge是一个极大值值抑制后的tensorlow低阈值high高阈值
- 分类:
- 不考虑低于
low的元素 - 高于
high的元素 记为强边缘,strong_mask记录位置 - 大于
low小于high的元素记为弱边缘,weak_mask记录位置
- 不考虑低于
- 将强边缘放入栈中,然后开始循环栈中的元素,先弹出栈中一个元素(强边缘),然后判断周围8个位置中是否存在弱边缘,如果存在,将弱边缘元素入栈,然后将当前元素输出到
output_index中,表示该强边缘元素处理结束。另外由于周围8个位置中的弱边缘已经入栈,为了防止重复入栈,将weak_mask对应位置设置为0。直到栈为空。 - 最后根据
output_index中的位置,返回最后的边缘检测图。
程序:
def hysteresis_threshold(nms_edge: torch.tensor, low: int, high: int) -> torch.tensor:
nms_edge = nms_edge.squeeze()
strong_mask = nms_edge >= high
weak_mask = (nms_edge > low) & (nms_edge < high).int()
output_index = []
# get strong_mask index
strong_index = torch.nonzero(strong_mask).tolist()
# create stack and push strong_index
stack = deque(strong_index)
while len(stack) > 0:
# pop item
item = stack.pop()
# get item index
i, j = item[0], item[1]
# get weak_mask index
local_index = torch.nonzero(weak_mask[i-1:i+2, j-1:j+2]).tolist()
for local_index_item in local_index:
# stack.append(weak_index[i])
weak_index_item = [i-1+local_index_item[0], j-1+local_index_item[1]]
stack.append(weak_index_item)
weak_mask[weak_index_item[0], weak_index_item[1]] = 0
output_index.append(item)
# create output tensor use output_index
output_index_tensor = torch.tensor(output_index) # (N, 2)
output = torch.zeros_like(nms_edge)
output[output_index_tensor[:, 0], output_index_tensor[:, 1]] = 255
return output
与opencv 算法对比
opencv canny算法:
import cv2
import numpy as np
from matplotlib import pyplot as plt
import time
if __name__ == '__main__':
img = cv2.imread('data/lena.png',0)
start_time = time.time()
edges = cv2.Canny(img,100,200)
print("time: ", time.time() - start_time)
plt.subplot(121),plt.imshow(img,cmap = 'gray')
plt.title('Original Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(edges,cmap = 'gray')
plt.title('Edge Image'), plt.xticks([]), plt.yticks([])
plt.show()
print("end")
# 保存图片
cv2.imwrite("data/opencv_edge_detect.png", edges)
同样的输入图片:
opencv 输出与本文pytorch 实现的输出一样:
都使用cpu 的情况下,opencv 的处理速度非常快:是本文pytorch 实现的30倍。
本文pytorch 实现需要的时间:time: 0.0885
而opencv 实现需要的时间:time: 0.0030
非常amazing, 竟然慢这么多,笔者还运行过别人
纯python的实现
,结论是非常慢。
sobel算子的 padding 对极大值抑制的影响
Canny算法中sobel算子padding的方式对极大值抑制的影响
参考
https://github.com/opencv/opencv/blob/2.2/modules/imgproc/src/canny.cpp https://github.com/adeveloperdiary/blog/tree/master/Computer_Vision/Canny_Edge_Detection